小说推广想要爆量,单靠野路子的离谱标题是不够的。小说推广的本质是内容付费,选一本受欢迎的好书才是起量的基础。
全民自媒体时代,内容创作门槛极低。看多了文章小说,孰优孰劣一眼便知。冲着标题和浮夸情节可能凑个热闹,真到付费章节,读者自然不会买单。
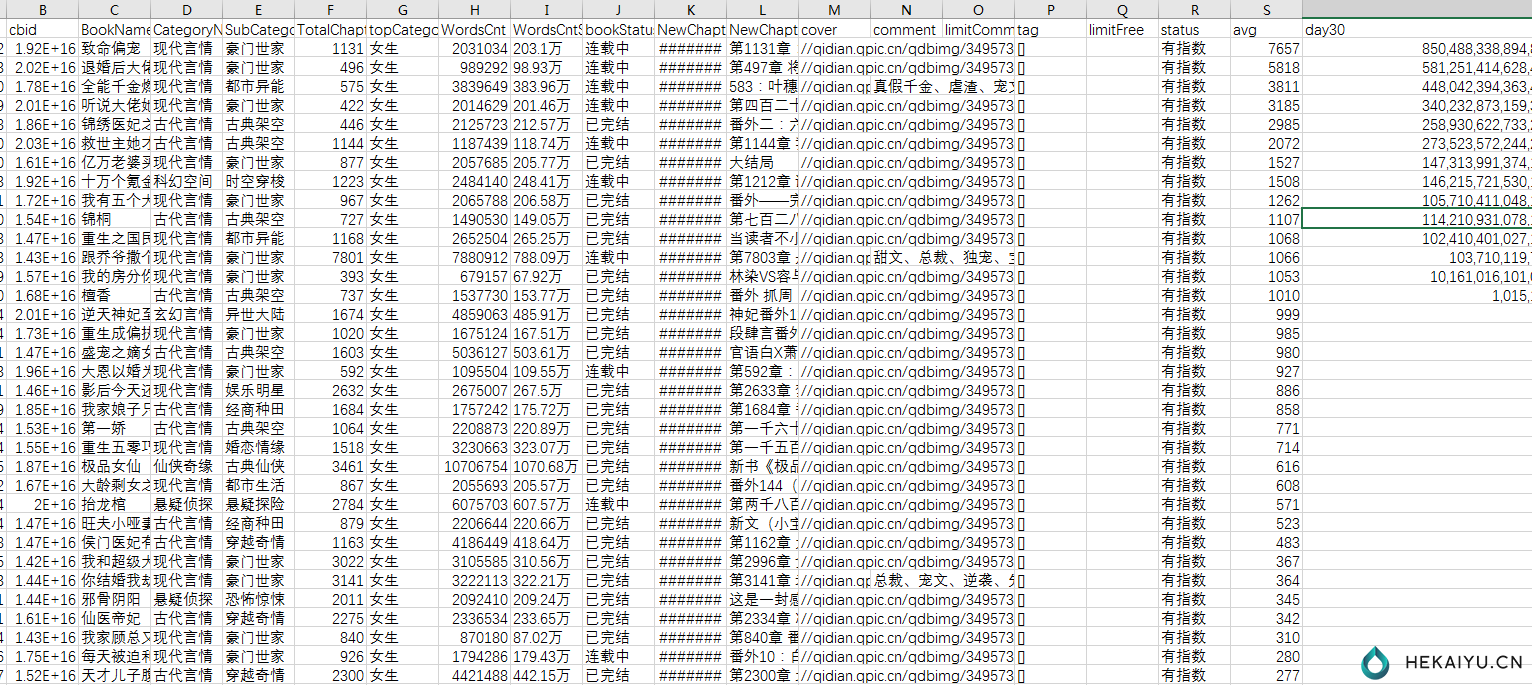
思路简单,以阅文后台为例,首先拿到后台所有的书名,然后查询该书的百度指数。拓展一下可以用主人公去查去,也可以查微信指数、微博指数等等。
import requests
import pandas as pd
import index_baidu
def checkw(word):
cookies=''
headers = {
'Connection': 'keep-alive',
'sec-ch-ua': '^\\^Google',
'Accept': 'application/json, text/plain, */*',
'sec-ch-ua-mobile': '?0',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
'index_csrftoken': '',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Dest': 'empty',
'Referer': 'https://index.baidu.com/v2/main/index.html',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cookie':cookies
}
params = (
('word', word),
)
response = requests.get('https://index.baidu.com/api/AddWordApi/checkWordsExists', headers=headers, params=params)
#print (response.json())
return response.json()
def yunwen(page):
cookies = ''
headers = {
'Connection': 'keep-alive',
'sec-ch-ua': '^\\^Google',
'Accept': 'application/json, text/plain, */*',
'sec-ch-ua-mobile': '?0',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Dest': 'empty',
'Referer': 'https://open.yuewen.com/new/library',
'Accept-Language': 'zh-CN,zh;q=0.9',
'cookie':cookies
}
params = (
('cbid', ''),
('page', page),
('version', '2'),
('category1', '2'),
('allwords', '-1'),
('category2', '-1'),
('isfinish', '-1'),
('level', '-1'),
)
response = requests.get('https://open.yuewen.com/api/wechatspread/bookSpread', headers=headers, params=params)
return response.json()
while nextpaget:
p=p+1
data=yunwen(p)
maxpage=data['data']['maxPage']
datalist+=data['data']['list']
print (p,maxpage)
if p>maxpage:
nextpaget=False
else:
pass
df=pd.DataFrame(datalist)
df.to_csv("datalist.csv",encoding="utf_8_sig")
for i in datalist:
#try:
# data=checkw(i['BookName'])
# try:
# status=data['data']['result'][0]['status']
# lastday=""
# except:
# status="有指数"
# words = [[{"name": i['BookName'], "wordType": 1}]]
# result=index_baidu.get_index_data(words)
# lastday=result[-1]
#except:
# status="失败"
# lastday=""
try:
words = [[{"name": i['BookName'], "wordType": 1}]]
status,avg,day30=index_baidu.get_index_data(words)
except:
status,avg,day30="失败","",""
i['status']=status
i['avg']=avg
i['day30']=",".join(day30)
returndatalist.append(i)
print (i['BookName'],status,avg)
df=pd.DataFrame(returndatalist)
df.to_csv("yuewen.csv",encoding="utf_8_sig")其他想法,欢迎交流!
