在正式开始介绍用python(webpy/flask)搭建网站前,先说一下自己学习python的一个大致流程。
主要是因为爬虫引起了我的兴趣,不指望有多么深入,只是希望能是自己的学习和部分工作变的更加方便快捷。
在学习爬虫是先了解了入门必看的两大库:reuqesets,bs一个负责链接网络一个负责结构化数据,这样抓抓段子、新闻就可以实现了;接下来就是数据的存储,不然抓的东西就没有意义了。list/dict就是基础,可以保存txt、xls基本够用,在做一个seo数据检查分析的系统时又恶补了sql,那些年逃过的课都是要换回来的啊。然后就是稍微特殊一些的需求了,比如爬js这种动态网站的数据要用到selenium,获取自己想要的数据的时候会用到re。
怕去了大量的数据怎么很好的使用就是个问题了,本人爱好斗图,前几天爬了6W多的表情,当时我就惊呆了、、

手握这么多资源,再也不怕斗图失败了。可是实际操作并非如此,6W多张表情,在windows下的文件夹里面查找起来卡的一匹,斗图的销量实在太低。后来就想着把数据导入mysql,python搭建一个简易的系统来查询就好了。python的web应用框架可谓非常极其之多,远非其他语言所能比,搭建起来就相当简单了。我一开始就选择了轻量级的webpy,上手快、操作简单,本着学习的态度又去研究了一下flask。

附上主要代码,看看我大python做个网站就是这么简单、、
from flask import Flask,render_template,request,jsonimport modelapp = Flask(__name__)@app.route('/')def GET():doutu=model.get_news()return render_template('index.html', name=doutu)@app.route('/sosuo', methods=['get'])def sosuo():keyword = request.values.get('keyword')doutu=model.get_sql(keyword)return render_template('sosuo.html', name=doutu,keyword=keyword)if __name__ == '__main__':app.run()
最后选用flask的原因主要是文档比较全,要学习的看这里:http://docs.jinkan.org/docs/flask/quickstart.html
用的是阿里云的学生机,别问我哪里来的学生机,这里是网站的成品:http://60.205.226.58:8080/
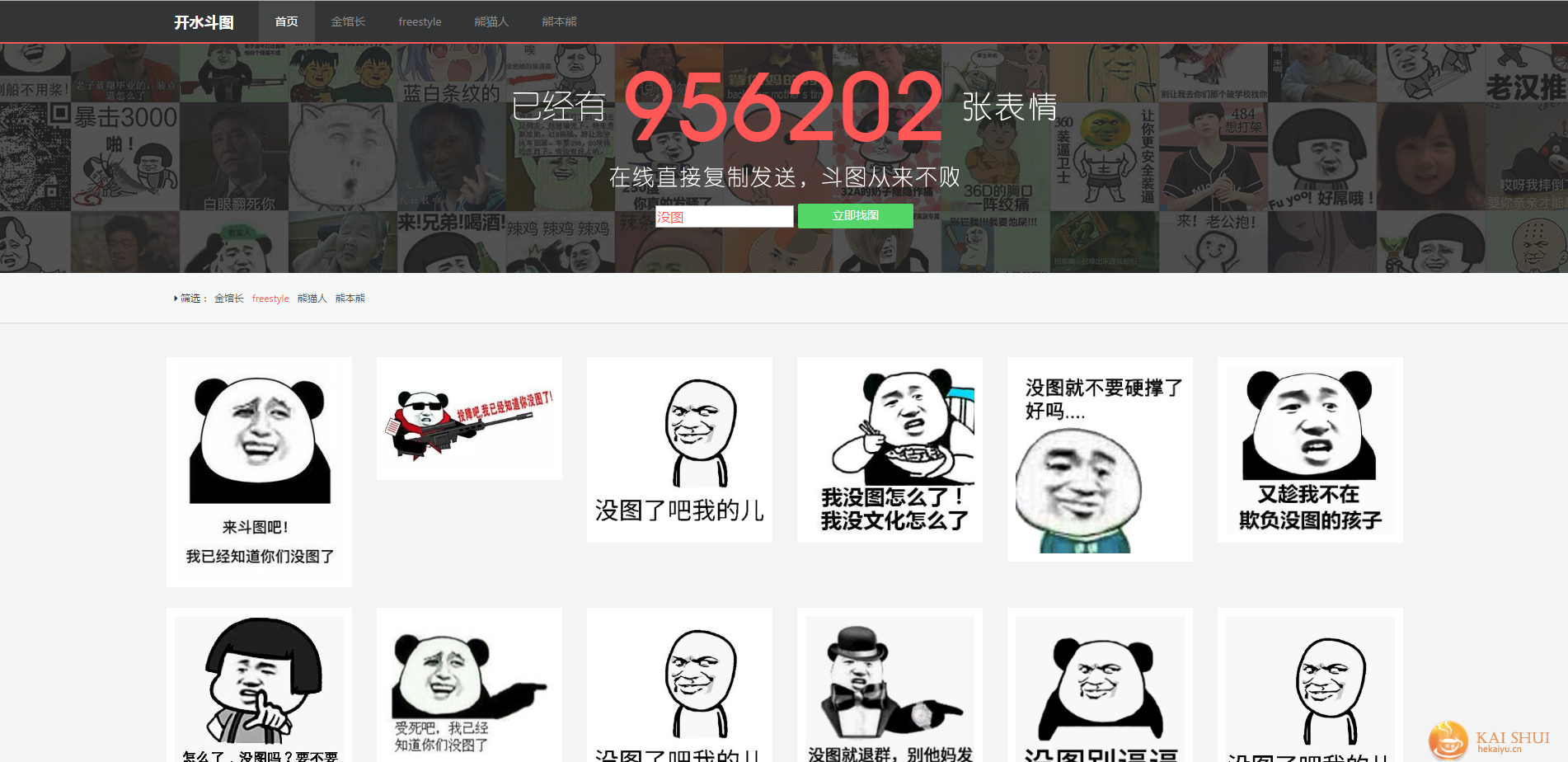

不懂布局,不知道该做什么页面咋搞啊