接触python有段时间了,文本处理、数据分析、绘图都是难啃的骨头,一直望而却步。matplotlib、pandas、正则对我来说难度都比较大,准备爬一波淘宝评论做分析学习,还是没有跳出爬虫的范畴,最终对仰望已久的整理QQ聊天记录下手。高筒同学总是聚少离多,电脑上保存有最近三年的班级群聊天记录,回忆一下过去也是很有必要的。
qq可以导出聊天记录的,但是原始数据是不适合拿来直接做分析的,如下。
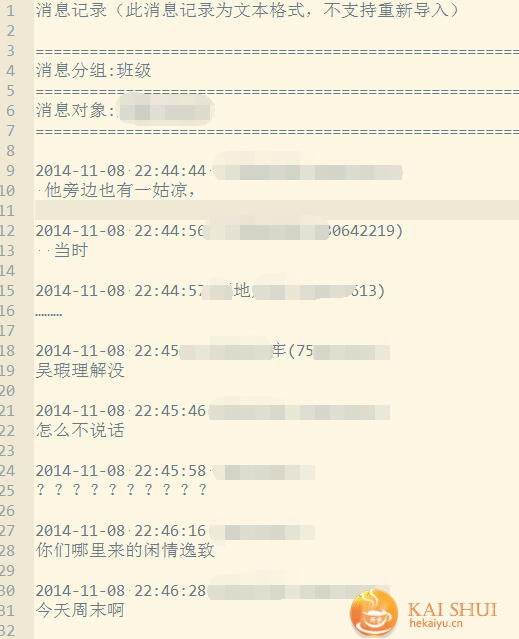
首先就要利用python对原始的数据进行整理,结果如下:
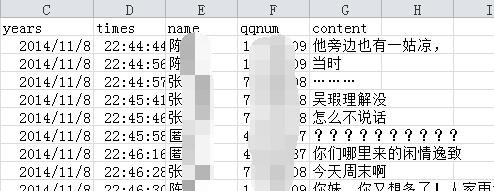
一、python整理qq聊天记录
1、利用正则匹配包含时间、备注、qq号码的这一行,进一步提取出时间、备注、qq等信息,需要注意的是qq分号码和邮箱、备注的修改也需要处理。
2、利用第一步的匹配,对文件做分割,将每一次聊天放入list,对换行特殊符号做处理。
3、判断以上步骤是否有误,第一步的list与第二步的长度相对则问题不大。(参考:http://blog.csdn.net/watfe/article/details/53420789)
4、将整理完成的数据保存excel,并且导入pandas分析。
二、python分析qq聊天记录
分析想要的数据,例如找出聊天最多的10天。
table_day=lc.resample('D',how=len).sort_values(["content"],ascending=False).head(10)
table_day['content'].plot(kind='bar')#对数据表按月进行汇总并生成新的月度汇总数据表
plt.xlabel(u'日期')
plt.ylabel(u'发言数')
plt.title(u'发言数排名前十')
plt.legend([u'聊天次数'], loc='best')
plt.show()
结果
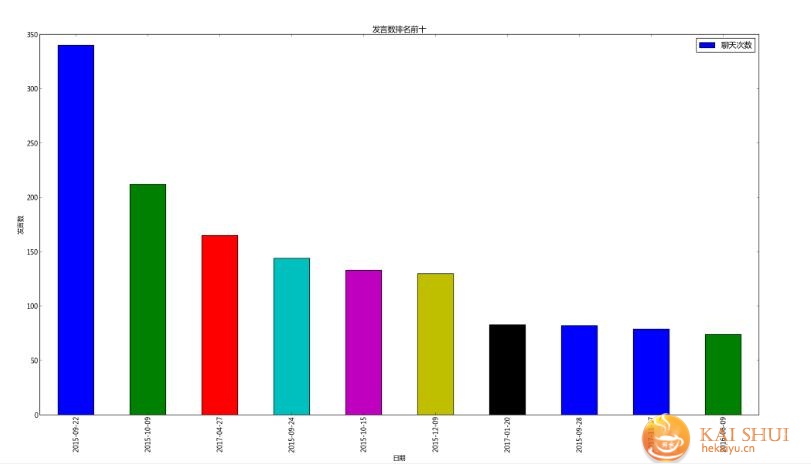
还可以画出聊天的人,聊天的时间段等等。
三、分析qq聊天内容
利用jieba/wordcloud分析初步聊天内容并绘图,斗图已经是大家不可或缺的话题了(导出的聊天记录中图片将以[图片]、[表情]保存)。

代码如下:
wordlist_after_jieba = jieba.cut(txt, cut_all = True)
wl_space_split = " ".join(wordlist_after_jieba)
wc = WordCloud(background_color = '#080808', #设置背景颜色
collocations=False,
#mask = "图片", #设置背景图片
max_words = 2000, #设置最大显示的字数
#stopwords = "图片,表情", #设置停用词
max_font_size = 50, #设置字体最大值
random_state = 30, #设置有多少种随机生成状态,即有多少种配色方案
)
my_wordcloud = wc.generate(wl_space_split)
plt.imshow(my_wordcloud)
plt.axis("off")
plt.savefig(bc+".png")
#plt.show()
通过pandas与wordcloud结合,画出每个群成员自己的聊天词云。

“没有”“工资”可以说相当精确了!

还有这样相当魔性的、、、

第一部分,输出的文件格式为什么还是txt文件,而不是excle
@ALAN 文章中的方式是txt,excel需要自己在设置了
请问能给一下第一部分整理用的代码吗
@苦学无路 文中有说的,参考代码
http://blog.csdn.net/watfe/article/details/53420789