在百度输入关键词搜索出现的列表页,大约2013年开始点击目标链接,跳转的时候是百度地址,经过百度解析,才真的跳到目标页面。360相对简单很多,利用python略微处理就可以得到搜索结果的真实URL链接。
在SEO中,经常需要排名好的网站究竟是哪家的。刚好最近做的工作需要去抓取一些数据,就遇到了这样的问题,又不想手动每天手动去点,可用以下方法去得到目标地址。
http://www.baidu.com/link?url=XyACAP-IHMK2wGbiKeQlE2uNUBqvTW25Ncog8p6irHC&wd=&eqid=b294bdf100009b3b00000005590ac8c7
http://www.so.com/link?url=http%3A%2F%2Fwww.hekaiyu.cn%2F&q=%E5%BC%80%E6%B0%B4%E7%BD%91%E7%BB%9C&ts=1493879032&t=38cfd50ae746259682fded99eda3939&src=haosou
模拟请求,得到百度真正的地址
这个速度要慢一点,就是先请求加密的链接,最后获取到真实的url。
import requests r = requests.get(target_url) return r.url
这个方法现在不怎么好用了,在我做项目的时候发现偶尔可以,和下面的一种方法类是,大概是只有部分或随机是302转跳(猜想),更多的返回的是200的状态。
根据Location获取百度真实URL
点击搜索结果加密链接之后,会向该链接发送GET,baidu这些连接大多进行了redirect(http 302),从服务器得到的回复中已经包含真实URL。

response = urllib2.urlopen(target_url) realurl = response.geturl() print(realurl)
200的状态下获取真实链接
搜索结果的链接返回200,这个页面通过js和refresh转跳到真实的链接,对于从百度爬取的加密的url,进行requests.get()时不允许跳转(allow_redirects=False)。这时候就需要去200页面提取真实连接了。
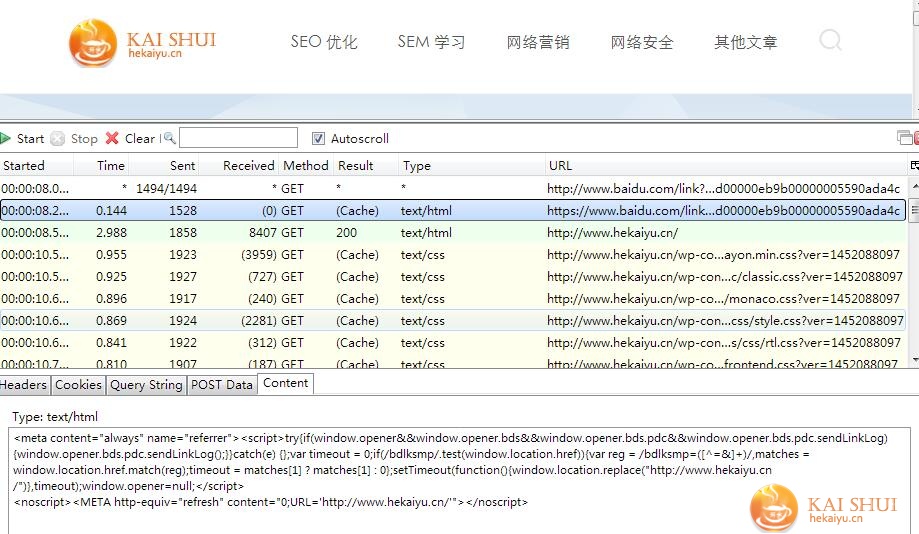
tmpPage = requests.get(tmpurl[0], allow_redirects=False)
urlMatch = re.search(r'URL=\'(.*?)\'', tmpPage.text.encode('utf-8'), re.S)
print urlMatch
这就可以了,更完整的判断http状态码,做对应处理。
for tmpurl in tmpURLs:
tmpPage = requests.get(tmpurl, allow_redirects=False)
if tmpPage.status_code == 200:
urlMatch = re.search(r'URL=\'(.*?)\'', tmpPage.text.encode('utf-8'), re.S)
originalURLs.append((urlMatch.group(1), tmpurl[1]))
elif tmpPage.status_code == 302:
originalURLs.append((tmpPage.headers.get('location'), tmpurl[1]))
else:
print 'No URL found!!'
python解码URL得到360搜索结果的链接
url编码是一种浏览器用来打包表单输入的格式,360搜索结果中包含的网站url解释url编码后。Url的编码格式采用的是ASCII码,而不是Unicode,这也就是说你不能在Url中包含任何非ASCII字符,我们需要解码后才方便后续的使用。当我们使用正则获取到360的连接后,直接用urllib解码就可以了。
url = urllib.unquote(target_url) print url
搜狗的就不说了,搜狗的放采集做的特别到位,跑一百下左右就不能跑了,开水还没有去突破。当然百度还有更加简单的获取方法,有时间再说!
