对于一个老网站来说,指数低的关键词是很容易拿到排名做百度seo优化的。关键就是关键词的布局要到位,现在很多教程或者培训都在说的关键词布局td-idf bm25算法,然而却很难做出效果。
为什么网站不能做出排名,究其原因要么是无法落地,要么就是落后老旧的内容。关键词指引着文章的内容,我们的关键词布局也可以说是内容布局,关键词用对了才能使得页面对用户有价值。
百度关键词seo原理
返璞归真,搜索引擎为信息检索用户提供快速、高相关性的信息服务。国内的搜索引擎百度很让我们比较快速的找到我们想要的结果。这也算是大家一直诟病百度,而又不得不用的原因吧。

td-idf bm25算法是搜索引擎来解决相关性的算法,没时间去捋,我这学历也捋不顺。最简单的办法还是抄,以前的文章提到挖掘同行网站,看他们怎么做。
关键词布局思路
这里我们可以进一步发挥,精细化操作。弄清楚优质对手(排名前两页)是怎么局部关键词的,我们学过来,基本就可以了。
有些人可能不理解,抄别人的怎么还能抄到别人前面去?因为我们是集合20个页面的优势与一体,并且剔除他们的毛病,你说能不优秀?
关键词布局方法
1、采集优质对手
采集目标关键词排名前20的优质对手页面,这个方法有很多python,火车头都可以实现。抓取百度搜索结果前二十的页面真实链接,然后访问保存页面内容,留着分析使用。
百度搜索排名API接口返回JSON数据格式:
https://www.baidu.com/s?wd=开水&pn=50&rn=50&tn=json
参数说明:
wd:关键词 、 pn : 查询偏移位置、 rn: 每页显示多少条,默认为10条,最多50条
2、分析优质对手
分析优质对手的标题、描述和页面内容,分别提取出页面的标题、描述、body标签内的文字内容。这里重点就是去除html标签和无用符号。
##############################
#过滤HTML中的标签
#将HTML中标签等信息去掉
#@param htmlstr HTML字符串.
##############################
def filter_tags(htmlstr):
#先过滤CDATA
re_cdata=re.compile('//<![CDATA[[^>]*//]]>',re.I) #匹配CDATA
re_script=re.compile('<s*script[^>]*>[^<]*<s*/s*scripts*>',re.I)#Script
re_style=re.compile('<s*style[^>]*>[^<]*<s*/s*styles*>',re.I)#style
re_br=re.compile('<brs*?/?>')#处理换行
#re_h=re.compile('</?w+[^>]*>')#HTML标签
re_dr = re.compile(r'<[^>]+>',re.S) #HTML标签
re_comment=re.compile('<!--[^>]*-->')#HTML注释
s=re_cdata.sub('',htmlstr)#去掉CDATA
s=re_script.sub('',s) #去掉SCRIPT
s=re_style.sub('',s)#去掉style
s=re_br.sub('n',s)#将br转换为换行
#s=re_h.sub('',s) #去掉HTML 标签
s=re_dr.sub('',s) #去掉HTML 标签
s=re_comment.sub('',s)#去掉HTML注释
#去掉多余的空行
blank_line=re.compile('n+')
s=blank_line.sub('n',s)
s=replaceCharEntity(s)#替换实体
return s
##替换常用HTML字符实体.
#使用正常的字符替换HTML中特殊的字符实体.
#你可以添加新的实体字符到CHAR_ENTITIES中,处理更多HTML字符实体.
#@param htmlstr HTML字符串.
def replaceCharEntity(htmlstr):
CHAR_ENTITIES={'nbsp':' ','160':' ',
'lt':'<','60':'<',
'gt':'>','62':'>',
'amp':'&','38':'&',
'quot':'"','34':'"',}
re_charEntity=re.compile(r'&#?(?P<name>w+);')
sz=re_charEntity.search(htmlstr)
while sz:
entity=sz.group()#entity全称,如>
key=sz.group('name')#去除&;后entity,如>为gt
try:
htmlstr=re_charEntity.sub(CHAR_ENTITIES[key],htmlstr,1)
sz=re_charEntity.search(htmlstr)
except KeyError:
#以空串代替
htmlstr=re_charEntity.sub('',htmlstr,1)
sz=re_charEntity.search(htmlstr)
return htmlstr
def repalce(s,re_exp,repl_string):
return re_exp.sub(repl_string,s)
获取到需要的内容后去除停止词使用结巴TF-IDF提取关键词,统计关键词的词频和占比。这里只是对单个竞争对手的处理,还需要综合对手页面页面,筛选80%页面都有的关键词,统计平均数做对比参考。
3、分析自身页面
分析自身标题、描述和页面内容,同分析单个竞争对手。
4、对比差异
和第二步的关键词均值对比,找出要添加的关键词,要减少的关键词,并且对比出具体数量量化标准。接下来做内容就相当简单了,给你300个关键词(有的关键词要出现数十次,我们去频次前五十的关键词数量也不小),写一篇800字的文章,这不是造句吗?
这里存在一个小问题,那就是黑帽的干扰,总有我们不知道的黑猫手法上排名,这就会使我们的结果产生偏差。所以在设计平均数的时候还要保留原数据(每个对手的数据),我们可以手动剔除这部分排名不正常的结果来比对。
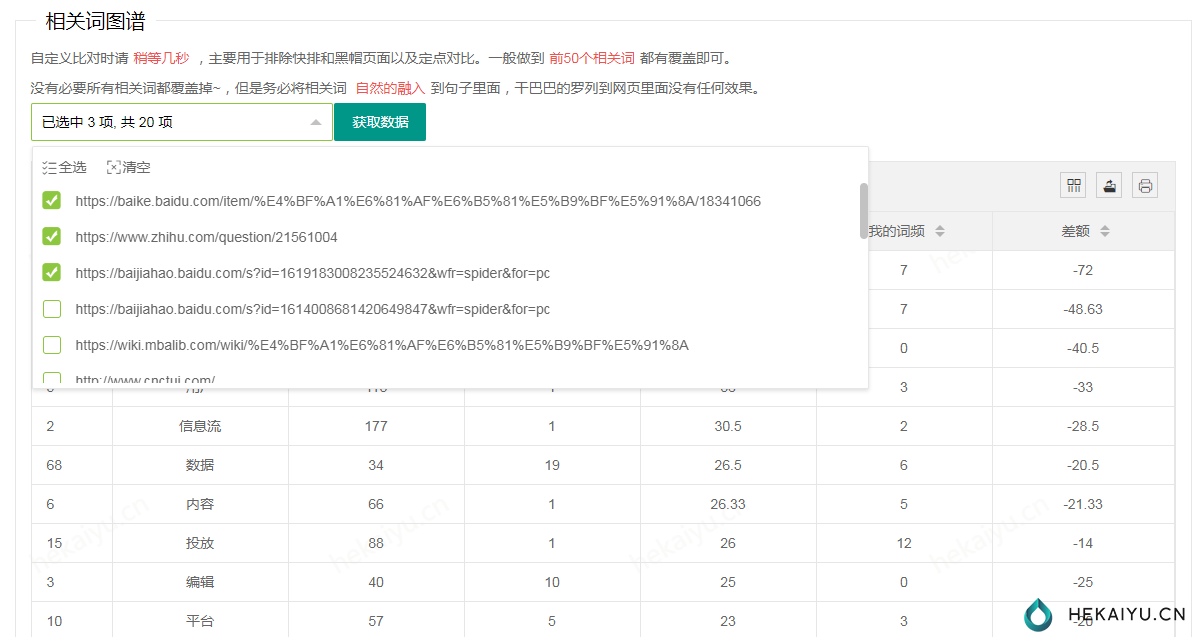
百度关键词seo案例
上面说的这套系统完成后我做了两个关键词测试,sem优化、信息流广告什么意思,前者栏目页,后者用的是文章页。
sem优化这个关键词长达一年没有排名。
06-16修改关键词布局,按照关键词布局系统参数扩充内容。
06-20百度前三页排名(部分地区首页)、谷歌首页排名,不到一周的时间排名前三页,效果可以说立竿见影。
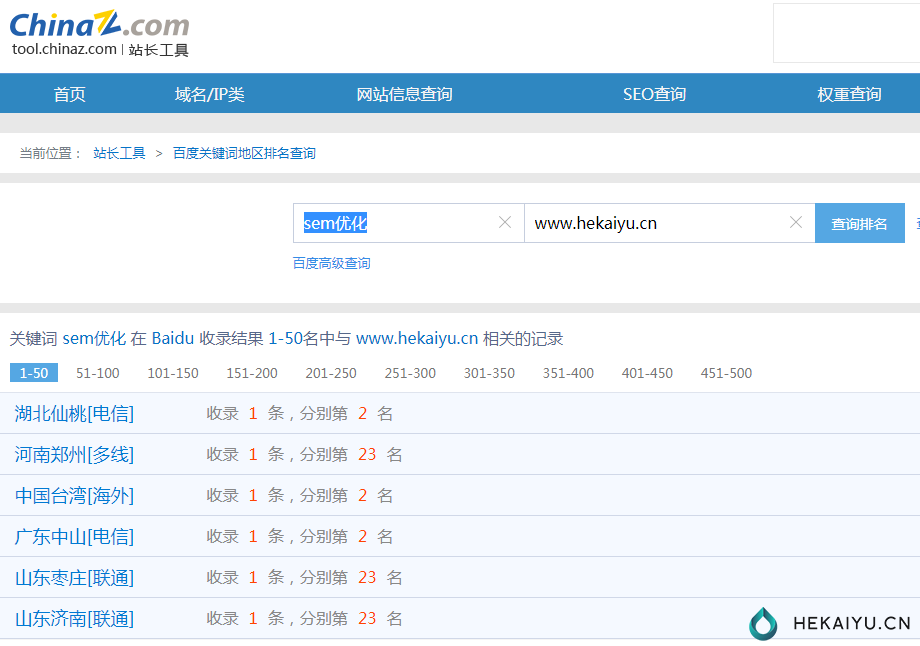
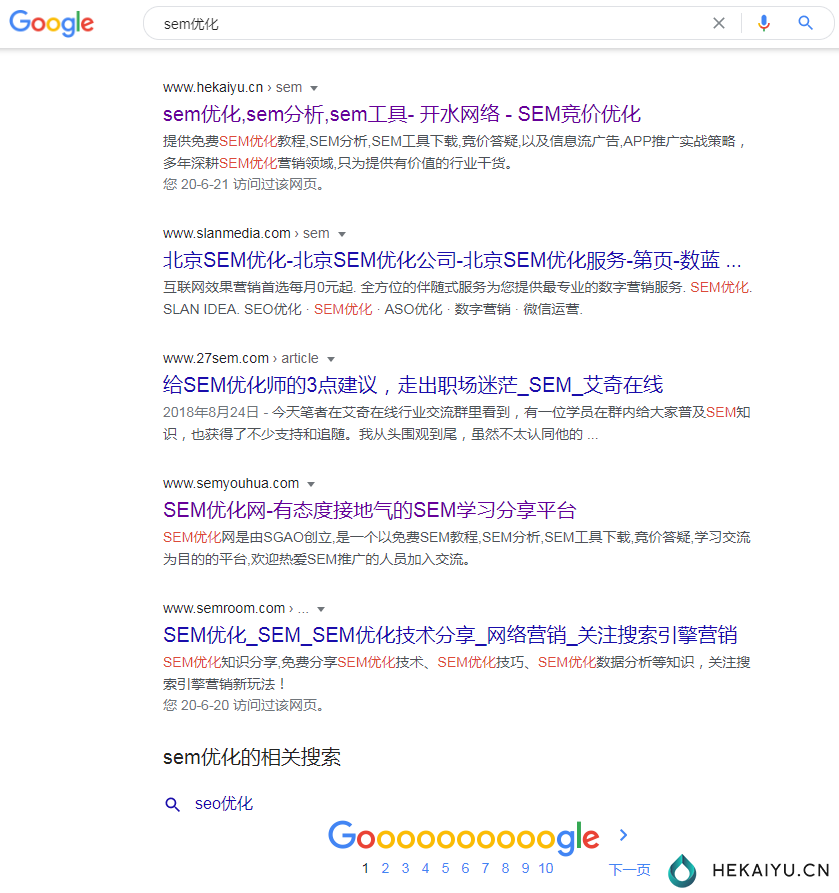
6月23端午节那天大部分百度排名首页第二,sem也到前三页。
6月27回落到06-20的数据百度前三页排名(部分地区首页),为什么?
seo优化常说的相关度30%、网站链接30%、用户行为40%。相关度相当于进入前三页的门槛,决定排名还要有链接和点击留存的支撑,在做布局的时候发现大量seo、网站、开户、运营的关键词,虽然指数不高,但是刷的还是很厉害。
开水不喜欢换友链,更没有刷点击,所以给了不到一周的前三,因为没有其他数据的支撑就有所回落。给各位的思考就是内容、外链、点击依旧是排名关键,想要有好的排名就要做得更多。
7月1日sem优化,重回百度第二,部分地区第一。
信息流广告什么意思,指数不高,但是竞争不少,我准备发布一些信息流的心得就做了这个入门关键词,第二天收录就排名第二页。

新手,学习中,多谢啦